


Section: New Results
Human activity capture and classification
Track to the future: Spatio-temporal video segmentation with long-range motion cues
Participants : Jose Lezama, Karteek Alahari, Ivan Laptev, Josef Sivic.
Video provides rich visual cues such as motion and appearance but also much less explored long-range temporal interactions among objects. We aim to capture such interactions and to construct powerful intermediate-level video representation for subsequent recognition. Motivated by this goal, we seek to obtain spatio-temporal oversegmentation of the video into regions that respect object boundaries and, at the same time, associate object pixels over many video frames. The contributions of this paper are twofold. First, we develop an efficient spatio-temporal video segmentation algorithm, that naturally incorporates long-range motion cues from the past and future frames in the form of clusters of point tracks with coherent motion. Second, we devise a new track clustering cost-function that includes occlusion reasoning, in the form of depth ordering constraints, as well as motion similarity along the tracks. We evaluate the proposed approach on a challenging set of video sequences of office scenes from feature length movies.
This work resulted in a publication [11] .
Density-aware person detection and tracking in crowds
Participants : Mikel Rodriguez, Ivan Laptev, Josef Sivic, Jean-Yves Audibert [INRIA SIERRA] .
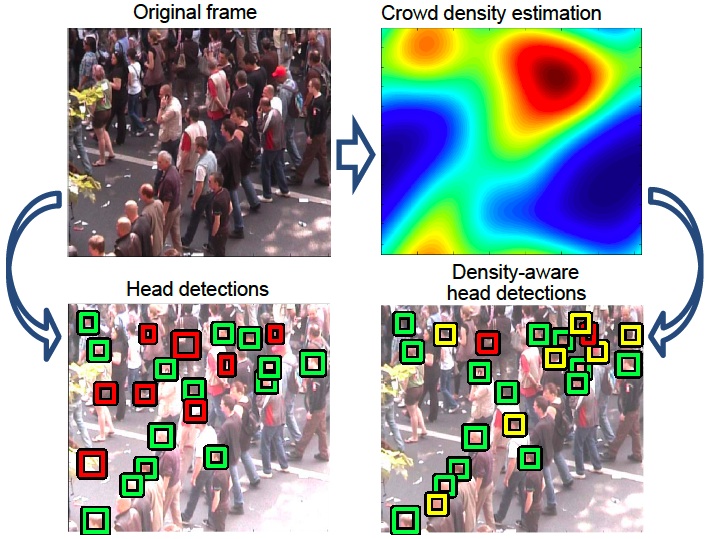
We address the problem of person detection and tracking in crowded video scenes. While the detection of individual objects has been improved significantly over the recent years, crowd scenes remain particularly challenging for the detection and tracking tasks due to heavy occlusions, high person densities and significant variation in people's appearance. To address these challenges, we propose to lever- age information on the global structure of the scene and to resolve all detections jointly. In particular, we explore con- straints imposed by the crowd density and formulate per- son detection as the optimization of a joint energy function combining crowd density estimation and the localization of individual people. We demonstrate how the optimization of such an energy function significantly improves person de- tection and tracking in crowds. We validate our approach on a challenging video dataset of crowded scenes. The proposed approach is illustrated in figure 5 .
This work has resulted in a publication [14] .
|
Data-driven Crowd Analysis in Videos
Participants : Mikel Rodriguez, Josef Sivic, Ivan Laptev, Jean-Yves Audibert [INRIA SIERRA] .
In this work we present a new crowd analysis algorithm powered by behavior priors that are learned on a large database of crowd videos gathered from the Internet. The algorithm works by first learning a set of crowd behavior priors off-line. During testing, crowd patches are matched to the database and behavior priors are transferred. We ad- here to the insight that despite the fact that the entire space of possible crowd behaviors is infinite, the space of distin- guishable crowd motion patterns may not be all that large. For many individuals in a crowd, we are able to find anal- ogous crowd patches in our database which contain sim- ilar patterns of behavior that can effectively act as priors to constrain the difficult task of tracking an individual in a crowd. Our algorithm is data-driven and, unlike some crowd characterization methods, does not require us to have seen the test video beforehand. It performs like state-of- the-art methods for tracking people having common crowd behaviors and outperforms the methods when the tracked individual behaves in an unusual way.
This work has resulted in a publication [15] .
Learning person-object interactions for action recognition in still images
Participants : Vincent Delaitre, Josef Sivic, Ivan Laptev.
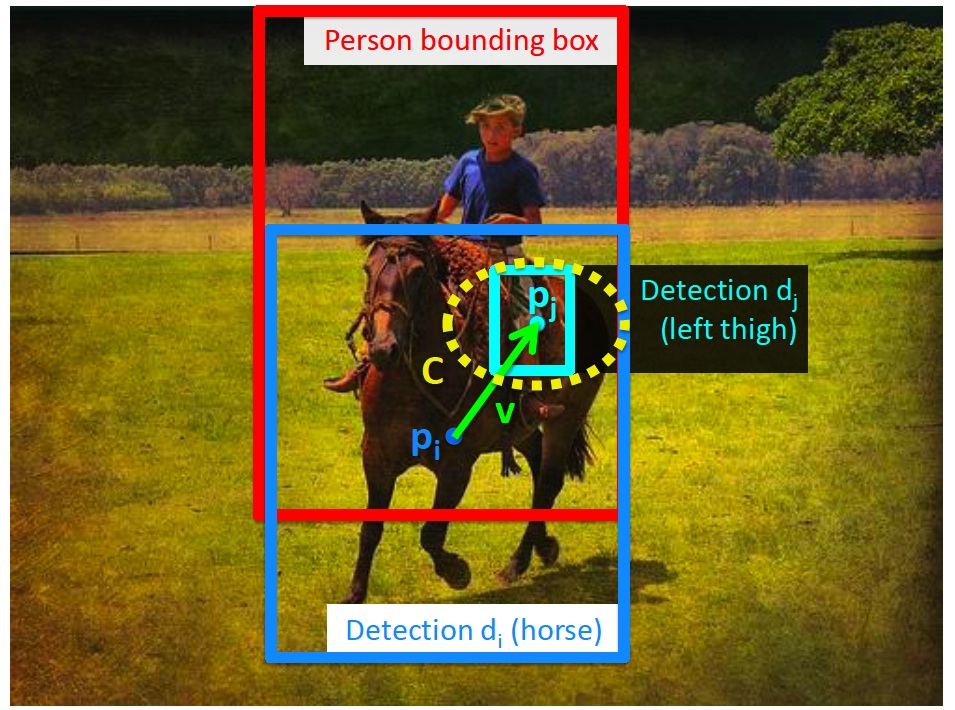
In this work, we investigate a discriminatively trained model of person-object interactions for recognizing common human actions in still images. We build on the locally order-less spatial pyramid bag-of-features model, which was shown to perform extremely well on a range of object, scene and human action recognition tasks. We introduce three principal contributions. First, we replace the standard quan- tized local HOG/SIFT features with stronger discriminatively trained body part and object detectors. Second, we introduce new person-object interaction features based on spatial co-occurrences of individual body parts and objects. Third, we address the combinatorial problem of a large number of possible interaction pairs and propose a discriminative selection procedure using a linear support vector machine (SVM) with a sparsity inducing regularizer. Learning of action-specific body part and object interactions bypasses the difficult problem of estimating the complete human body pose configuration. Benefits of the proposed model are shown on human action recognition in consumer photographs, outperforming the strong bag-of-features baseline. The proposed model is illustrated in figure 6 .
This work has resulted in a publication [8] .
|
People Watching: Human Actions as a Cue for Single View Geometry
Participants : David Fouhey [CMU] , Vincent Delaitre, Abhinav Gupta [CMU] , Ivan Laptev, Alexei Efros [CMU] , Josef Sivic.
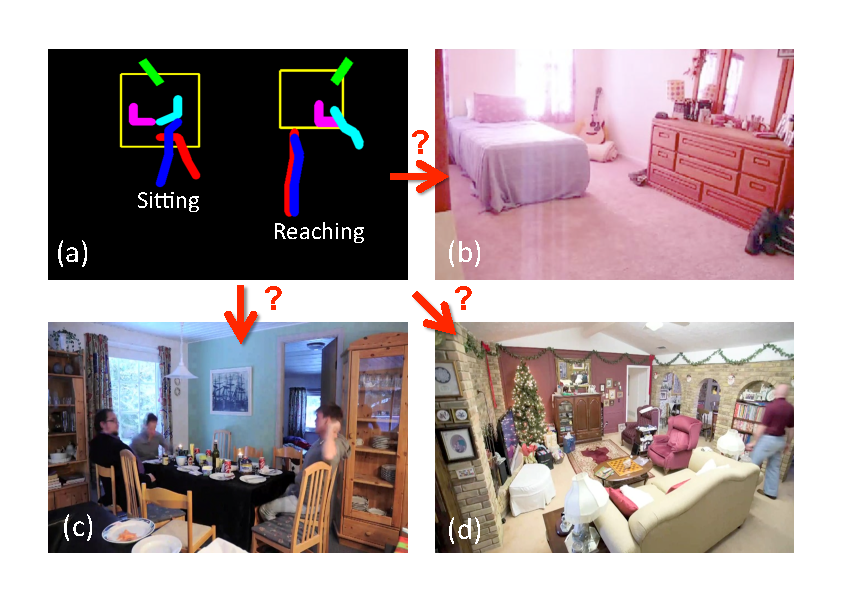
We present an approach which exploits the coupling between human actions and scene geometry. We investigate the use of human pose as a cue for single-view 3D scene understanding. Our method builds upon recent advances in still-image action recognition and pose estimation, to extract functional and geometric constraints about the scene from people detections. These constraints are then used to improve state-of-the-art single-view 3D scene understanding approaches. The proposed method is validated on a collection of single-viewpoint time-lapse image sequences as well as a dataset of still images of indoor scenes. We demonstrate that observing people performing different actions can significantly improve estimates of scene geometry and 3D layout. The main idea of this work is illustrated in figure 7 .
This work is in submission to CVPR 2012.
|
Joint pose estimation and action recognition in image graphs
Participants : K. Raja [INRIA Rennes] , Ivan Laptev, Patrick Perez [Technicolor] , L. Osei [INRIA Rennes] .
Human analysis in images and video is a hard problem due to the large variation in human pose, clothing, camera view-points, lighting and other factors. While the explicit modeling of this variability is difficult, the huge amount of available person images motivates for the implicit, datadriven approach to human analysis. In this work we aim to explore this approach using the large amount of images spanning a subspace of human appearance. We model this subspace by connecting images into a graph and propagating information through such a graph using a discriminatively trained graphical model. We particularly address the problems of human pose estimation and action recognition and demonstrate how image graphs help solving these problems jointly. We report results on still images with human actions from the KTH dataset.
This work has resulted in a publication [13] .